AIPodcasts Review: Is it Legit? A Deep Dive into the 2026 AI Podcast Revolution

In 2026, the digital landscape is dominated by audio-visual content, and podcasts have become the primary vehicle for building authority. But for most beginners, the cost of microphones, cameras, and editing software remains a massive barrier to entry. This AIPodcasts Review explores whether you can truly skip the studio and let artificial intelligence do the heavy lifting for you.
AIPodcasts is a legitimate, cloud-based AI platform that automates the creation, editing, and distribution of multi-speaker audio and video podcasts from simple text. By utilizing advanced voice cloning and digital avatars, it allows beginners to launch professional-grade shows on Spotify, Apple, and YouTube without recording a single word manually. It is a highly effective tool for content scaling and agency services.
What Exactly is AIPodcasts?
AIPodcasts is an all-in-one “Gen-AI” production suite designed to eliminate the technical hurdles of podcasting. Unlike basic text-to-speech tools, this system focuses on the nuances of human interaction, including natural pauses, varying tones, and multi-speaker dynamics. It is built specifically for marketers, authors, and small business owners who need high-quality content without the typical $5,000 studio investment.
The software operates in the cloud, meaning you don’t need a high-end computer to render video. It uses synthetic media technology to create “talking head” video podcasts where AI avatars speak your script with perfect lip-syncing. This shift from manual production to AI-driven generation marks a significant turning point for the creator economy in 2026.
The Technology Behind the Scenes
The platform leverages proprietary neural networks to handle voice synthesis. It doesn’t just read text; it interprets the context to apply the right emotional weight to words. This results in a listening experience that feels less like a robot and more like a human conversation, which is critical for listener retention in the modern era.
Get Started with AIPodcasts and Launch Your Show Today
How AIPodcasts Works for Beginners

One of the primary reasons this tool is trending in 2026 is its “Type-and-Create” workflow. You don’t need to be a sound engineer or a video editor to get a professional result. The process is streamlined into three distinct phases that take most users less than ten minutes to complete from start to finish.
Step 1: Content Input and Scripting
You begin by providing the core idea or existing content. You can paste a blog post, a URL, or even a few keywords. The AI then generates a structured podcast script, often formatted as a conversation between two or more hosts. This ensures the content is engaging rather than a dry monologue.
Step 2: Customization and Character Selection
Once the script is ready, you choose your “hosts.” You can select from a library of over 100 realistic AI voices or use the voice cloning feature to replicate your own. If you are creating a video podcast, you also select an AI avatar or upload your own footage to serve as the visual representation of the speaker.
Step 3: Rendering and Distribution
After reviewing the preview, you click “Generate.” The AI mixes the audio, adds background music, cleans up any digital noise, and renders the final video. From there, you can use the built-in 1-click distribution tool to push the episode to YouTube, Spotify, and Apple Podcasts simultaneously.
Core Features That Define the Platform
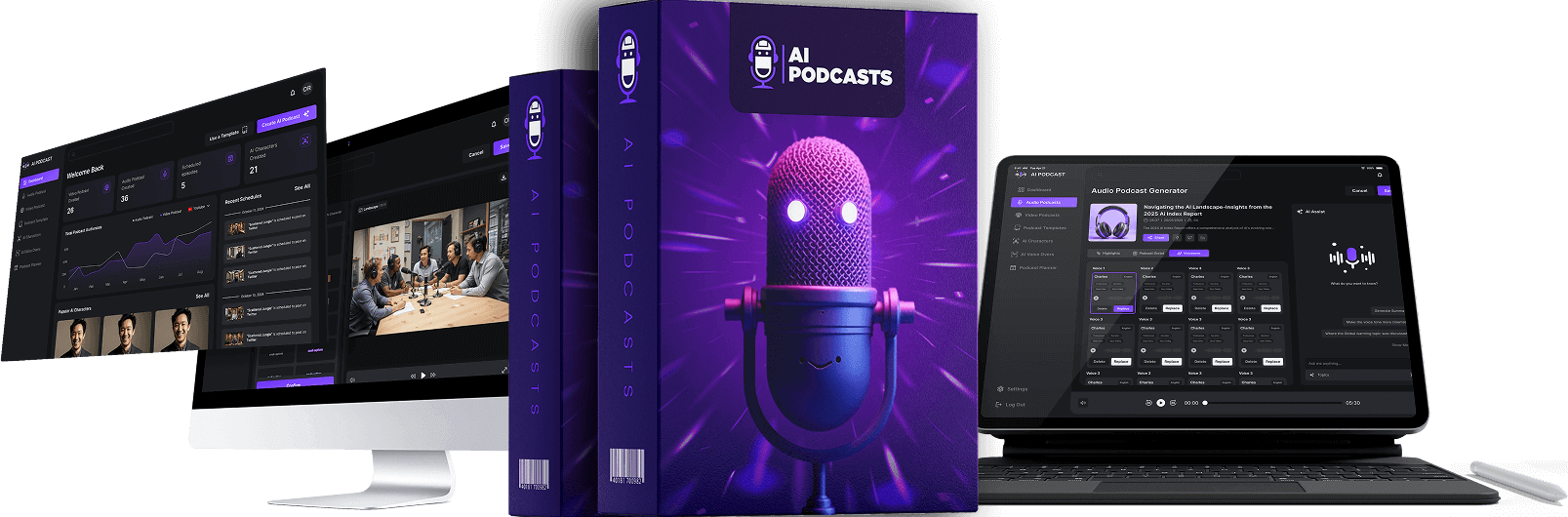
To understand the value of AIPodcasts, we have to look at the specific features that differentiate it from the flood of AI tools available in 2026. These features are designed to maximize the “human” feel of the output, which is the most important factor for success in the current algorithm.
Multi-Way AI Conversations
Most AI voice tools only support a single speaker. AIPodcasts allows for up to four distinct voices in a single episode. This allows you to create “roundtable” discussions or interview-style shows where the AI speakers interact, interrupt each other slightly, and laugh, creating a much more dynamic listening experience.
AI Video Avatars and Face-Swapping
Video is the fastest-growing segment of the podcasting world. This tool creates high-definition video podcasts where an avatar speaks your content. With face-swapping technology, you can even put your own face onto a professional actor’s body, giving your brand a consistent, professional look without you ever having to sit in front of a camera.
Automatic Content Repurposing
For bloggers and researchers, the ability to turn a 2,000-word article into a 15-minute podcast episode is a game-changer. It allows you to dominate multiple platforms (YouTube, Spotify, Google Search) using the same core piece of information. This multi-channel approach is the secret to high-authority SEO in 2026.
Pros and Cons of Using AIPodcasts
No product is perfect, and part of a high-authority AIPodcasts Review is looking at the limitations. While the tool is revolutionary, it serves a specific purpose and might not be the right fit for everyone depending on their creative goals.
The Pros
-
Extremely Cost-Effective: You save thousands on equipment, hosting, and editing services.
-
Massive Time Savings: What used to take a week of production now takes less than fifteen minutes.
-
No “Mic-Shyness”: Perfect for introverts or those who don’t like the sound of their own voice.
-
Commercial Rights Included: The ability to sell podcasting as a service to clients is a major income stream.
-
High-Quality Output: 4K video and HD audio ensure your content doesn’t look “cheap” or amateur.
The Cons
-
Learning Curve: While simple, mastering the “4-way conversation” settings takes a bit of practice.
-
AI Nuance: While 95% human-like, very eagle-eared listeners might still detect the synthetic nature of the audio in certain complex sentences.
-
Subscription for Updates: While there is a one-time fee for the base version, some advanced monthly updates require an OTO (One-Time Offer) upgrade.
Check Out the AIPodcasts Bundle Deal for Full Access
AIPodcasts vs. Traditional Podcasting
In 2026, the choice is between the “Old Way” and the “AI Way.” If you are a celebrity with a massive budget, traditional recording might still be your preference. However, for 99% of marketers and beginners, the comparison is heavily skewed in favor of automation.
Cost Comparison
A traditional setup requires a high-quality XLR microphone ($300), an audio interface ($200), a 4K camera ($800), lighting ($200), and editing software subscriptions ($50/mo). AIPodcasts offers the same output for a one-time payment of $37 during its launch phase. The ROI is mathematically undeniable.
Production Speed
Recording a 30-minute episode traditionally takes 30 minutes of recording, 2 hours of editing, 1 hour of show note writing, and 30 minutes of distribution. AIPodcasts handles all of this in roughly 10 minutes of total human effort. This allows a single creator to run five or ten shows simultaneously, whereas a traditional podcaster can barely manage one.
Is AIPodcasts Worth It for Beginners?
The short answer is yes. If your goal is to build an audience, drive traffic to your products, or start a side hustle as a digital agency, this tool provides the lowest barrier to entry in the history of the medium. You don’t need “talent” in the traditional sense; you only need good ideas and the ability to click a few buttons.
The inclusion of commercial rights is perhaps the biggest “legitimacy” factor. It means the creators expect you to use this tool for business. You can go to sites like Upwork or Fiverr and offer “Podcast Production Services” and use AIPodcasts to fulfill the orders, essentially creating a hands-free business model.
Key Takeaways
-
AIPodcasts uses Gen-AI to create audio and video podcasts from text.
-
The platform supports 4-way conversations and realistic voice cloning.
-
It includes 1-click publishing to major platforms like Spotify and YouTube.
-
It is designed for beginners who want to avoid high equipment costs.
-
The Commercial License allows users to sell these podcasts as a service.
FAQs
1. Do I need to pay for hosting separately?
No, AIPodcasts includes built-in hosting and distribution tools, meaning you can push your content to major directories directly from the dashboard without needing an external hosting provider like Libsyn or Anchor.
2. Can I use my own voice for the AI episodes?
Yes, the software includes a voice cloning feature. You simply upload a short sample of your speech, and the AI creates a digital clone that you can use to “read” any script you enter in the future.
3. Is there a limit to how many podcasts I can create?
The Front-End version usually has a limit (around 50 podcasts), but the “Unlimited” OTO upgrade allows for up to 500 podcasts per month, which is more than enough for even the most aggressive content creators.
4. Will my podcast get banned for using AI voices?
Platforms like YouTube and Spotify do not ban AI content as long as it provides value and follows their standard community guidelines. In fact, many top-tier channels in 2026 use synthetic voices for narration.
5. What happens if I don’t like the product?
The product comes with a 14-day money-back guarantee. If the tool doesn’t fit your workflow or you find the voices aren’t to your liking, you can request a full refund through their support desk.
Final Verdict: Is it Legit?
After analyzing the features, the pricing structure, and the output quality, it is clear that AIPodcasts is a powerful, legitimate tool for the 2026 market. It effectively democratizes a medium that was once reserved for those with deep pockets and professional vocal training. While it won’t replace the deep, soulful connection of a top-tier human interviewer, it is the perfect solution for 90% of business-related content needs.